

 |
相關閱讀 |
(轉)DirectX支配游戲!歷代GPU架構全解析
|
>>> 技術話題—商業文明的嶄新時代 >>> | 簡體 傳統 |
NVIDIA與ATI(AMD)的GPU之戰,遠比Intel和AMD的CPU之戰有意思,畢竟雙方的實力差距并沒有那么懸殊,經常斗得是難解難分。N/A的連年征戰給我們帶來無與倫比游戲畫面和優秀產品的同時,也為喜歡IT技術的朋友帶來了許多樂趣和談資,只有深愛硬件技術的朋友才能有所體會。
掐指一算,從GPU誕生至今雙方都已推出了十代產品,每一代產品之間的對決都令無數玩家心動不已,而其中最精彩的戰役往往在微軟DirectX API版本更新時出現。雖說勝敗乃兵家常事,但NVIDIA和ATI每一代產品誰更強大似乎有某種規律可循,而且與DirectX有著某種微妙的關系。

相信很多人都有這種感覺,似乎誰與微軟走的更近,誰能最先支持新版DirectX API,誰就能占據更多的優勢。但也有例外,比如DX8.1對于Radeon 8500的幫助有限,DX10.1也沒有給HD3000帶來好運。其實這些只是表象,如果我們能夠透過現象看其本質的話,就會發現DirectX與GPU的架構是有直接關系的,而GPU架構的優劣直接了決定一代產品的成敗。
所以,今天我們就拋開GPU的晶體管數、管線/流處理器規模、工藝、頻率、功能等等技術參數不談,我們將關注的焦點集中在GPU體系架構方面。看看每逢DirectX版本有重大更新時,NVIDIA與ATI是如何博弈的,克敵制勝的關鍵到底是什么?
在DirectX 5.0以前,這個被微軟整合在Windows操作系統內部的圖形API并沒有現在這么風光,當時的顯卡和游戲都以支持OpenGL和Glide(3DFX的專用API)為榮,DirectX在持續不斷的改進與發展,但始終都沒能超越對手,一方面基于DOS系統的Windows還不夠強大,另一方面微軟的影響力還沒到左右游戲開發商和芯片廠商的地步。
直到Windows 95發布之后,全新的圖形界面讓整個業界都興奮不已,90%的占有率直接帶動了整個行業的需求,也迫使全球軟硬件廠商都不得不向其靠拢。此時整合Win95整合的DirectX 6.0也有了足夠的實力與OpenGL/Glide分庭抗力,在技術特性不輸與人的情況下,DirectX的影響力與日劇增。
● DirectX 7.0確定權威:核心技術T&L
DirectX 7.0是一次革命性的改進,其最大的特色就是支持Transform & Lighting(T&L,坐標轉換和光源)。

3D游戲中的任何一個物體都有一個坐標,當此物體運動時,它的坐標發生變化,這指的就是坐標轉換;3D游戲中除了場景+物體還需要燈光,沒有燈光就沒有3D物體的表現,無論是實時3D游戲還是3D影像渲染,加上燈光的3D渲染是最消耗資源的。


基于T&L技術的演示Demo
在T&L問世之前,位置轉換和燈光都需要CPU來計算,CPU速度越快,游戲表現越流暢。使用了T&L功能后,這兩種效果的計算用顯卡核心來計算,這樣就可以把CPU從繁忙的勞動中解脫出來,讓CPU做他該作的事情,比如邏輯運算、數據計算等等。換句話說,DX7顯卡用T&L渲染游戲時,即使沒有高速的CPU,同樣能能流暢的跑3D游戲。
DirectX 7.0架構:首顆GPU GeForce 256
★ 首顆GPU誕生:GeForce 256(NV10)
T&L優秀的特性成為當時業界關注的焦點,那么首款支持DX7與T&L的顯卡自然備受期待,NVIDIA的GeForce 256就是這樣一款劃時代的產品,為了突出它先進的技術特性,NVIDIA將GeForce 256的顯示核心稱為GPU(Graphic Processing Unit,圖形處理器)。
GeForce 256所采用的核心技術除了硬件T&L之外,還有立方環境材質貼圖、頂點混合、紋理壓縮和凹凸映射貼圖、雙重紋理四像素、256位渲染引擎等諸多先進技術。在性能大幅提升的同時,3D游戲的畫面得到了質的提升。
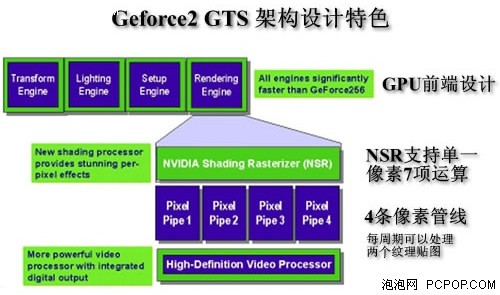
此后發布的GeForce 2 GTS就是GeForce 256的提速版本,架構、規格和技術沒有多少改變。因此可以說GeForce 256就已經確立了當今GPU的整體架構雛形,我們可以看到它擁有專門的坐標轉換與光源引擎,還有裝配引擎、渲染管線、后期處理模塊等等,這些功能單元基本都被沿用至今。
★ 兩強爭霸局面形成:Radeon 256
在DX7大勢所趨的局面下,ATI也發布了首款DX7顯卡,其命名都與NVIDIA驚人的一致——Radeon 256,由此掀開了NVIDIA與ATI、GeForce與Radeon爭霸的局面。

Radeon 256獨特的單管線3紋理架構
Radeon 256同樣支持硬件T&L、環境貼圖和凹凸貼圖,還支持Hyper及和DOT3壓縮技術,Radeon 256只有兩條渲染管線,但每條管線擁有多達3個紋理單元,而GeForce 256每條管線只有1一個紋理單元,GeForce 2 GTS才改進為2個。但遺憾的是Radeon 256的第3個貼圖單元直到它退市的時候也沒有任何程序能夠支持它,同時令人詬病的驅動也令用戶大為惱火。
Radeon 256及其衍生的Radeon VE/LE/SE等都是優秀的產品,技術與架構不輸給GeForce系列,功能甚至還更豐富,但糟糕的軟硬件支持度導致它無法同GeForce相抗衡,口碑和市場都不如人意。
★ 小結:DX7架構平分秋色,硬件規格決定性能
GeForce 256與Radeon 256的基本架構是相同的,不同的是管線設計,GeForce 256擁有更多4條管線,但紋理單元也只有4個;Radeon 256雖然只有2條管線,但每管線擁有3個紋理單元,而且工作頻率很高,因此在理論性能上占優勢。
在當時來說,游戲大量使用了各種紋理貼圖,因此對紋理單元提出了很高的要求,所以NVIDIA在GeForce 2 GTS當中改進為單管線雙紋理。NVIDIA管線:紋理=1:2、ATI管線:紋理=1:3的架構都維持了很多年,直到DX9時代才有了較大的變化。
● DirectX 8.0:引入像素和頂點兩大渲染管線
面向圖形計算,讓GPU逐漸找到了自己的方向,那就是給予用戶更真更快地視覺體驗,但是GPU架構也遇到一些問題亟待解決。首要問題就是,要實現更加復雜多變的圖形效果,不能僅僅依賴三角形生成和固定光影轉換,雖然當時游戲畫面的提高基本上都是通過大量的多邊形、更復雜的貼圖來實現的。
但后期的發展中,頂點和像素運算的需求量猛增。每個頂點都包含許多信息,比頂點上的紋理信息,散光和映射光源下表現的顏色,所以在生成多邊形的時候帶上這些附加運算,就可以帶來更多的效果,但這也更加考驗頂點和像素計算能力。
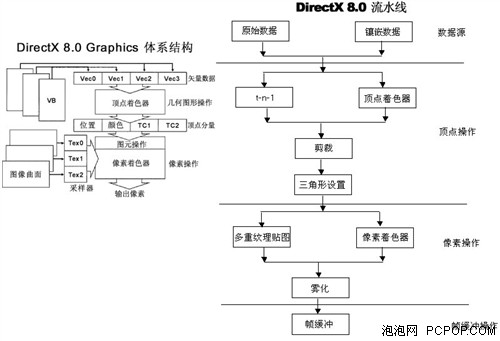
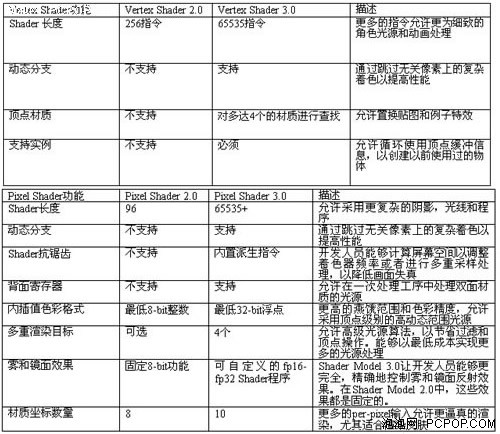
2001年微軟發布了DirectX 8.0,一場新的顯卡革命開始,它首次引入了ShaderModel的概念,ShaderModel就相當于是GPU的圖形渲染指令集。其中像素渲染引擎(Pixel Shader)與頂點渲染引擎(Vertex Shader)都是ShaderModel 1.0的一部分,此后每逢DirectX有重大版本更新時,ShaderModel也會相應的升級版本,技術特性都會大大增強。
與DX7引入硬件T&L僅僅實現的固定光影轉換相比,VS和PS單元的靈活性更大,它使GPU真正成為了可編程的處理器,時至今日DX11時代ShaderModel都在不停地更新,以便渲染出更逼真更完美的畫面。這意味著程序員可通過它們實現3D場景構建的難度大大降低,但在當時來說可編程性還是很弱,GPU的這一特性還是太超前了。






DX8動態光影效果展示:變色龍和不同角度的人臉
DirectX 8.0當中的Pixel Shader和Vertex Shader的引入,使得GPU在硬件邏輯上真正支持像素和頂點的可編程,反映在特效上就是動態光影效果,當時波光粼粼的水面都是第一次展現在玩家面前。
但是DX8的普及之路并不順暢,主要是因為當時的DX8顯卡都定位太高,NVIDIA和ATI雙方都沒有推出過低端DX8顯卡,熱賣的產品都是DX7,直到DX9誕生之后,雙方才把昔日高端的DX8顯卡當作低端產品處理。
★ 首款DX8顯卡:GeForce 3 Ti
在DX8之前,無論NVIDIA還是ATI,都在強調顯卡前端及后端輸出。而Shader理念提出之后,雙方逐漸將競爭重點放在了顯卡的渲染核心部分——像素渲染管線和頂點渲染管線,無論是GeForce 3 Ti還是Radeon 8500都內置的規格和頻率更強的PS和VS單元。當然也對顯卡的后端ROP(光柵化引擎,負責完成像素的輸出)也做了相應的改進,各種各樣的多重采樣AA模式和材質過濾技術逐步得以實現。
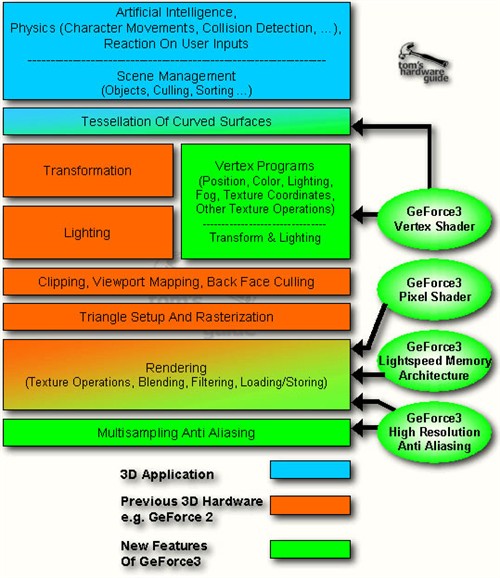
上圖就是GeForce 3的核心架構圖,可以看出,由于DX8渲染模式的改變,GeForce 3相對于DX7的GeForce 2/256有了天翻地覆的變化,一半以上的模塊需要重新設計(綠色部分)。
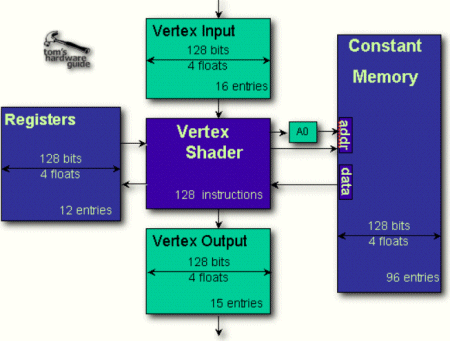
GeForce 3的頂點管線設計
硬件規格方面,GeForce 3依然只有4條渲染管線,每條管線內置2個紋理單元,這與上代的GeForce 2沒有區別。但是GeForce 3的核心晶體管數竟然是GeForce 2的兩倍以上,額外的晶體管大都用在了頂點管線部分,雖然它只有一個頂點著色單元。這個頂點著色單元其實就是一個4D SIMD(單指令多數據流)處理器,可以計算最多16項數據的頂點,這在當時來說運算能力已經非常富裕了。
不過,主流的游戲還是基于DX7開發,因此GeForce 3的VS單元很多時候都派不上用場,由此導致GeForce 3在DX7游戲當中領先GeForce 2 Ti的優勢并不大,畢竟它們的像素渲染管線和紋理單元數目是相同的,頻率也沒有提升太多。
★ ATI直上DX8.1:Radeon 8500
DX8方面ATI再次落后于NVIDIA,但后發制人也有好處,ATI直接采用了微軟更新的DX8.1 API,因此在硬件特性方面要更勝一籌。不過DX8.1的改進極為有限,只是改進了大紋理水波紋的效能,未能得到整個業界的重視。
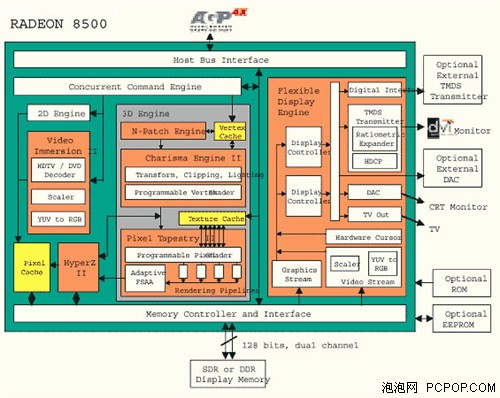
Radeon 8500與DX7版的Radeon系列相比,架構上也產生了翻天覆地的變化,除了加入頂點引擎外,更多尚處于實驗性的技術都被置于其中,而且2D輸出部分的功能更為豐富,可以說在技術和功能方面完全超越了GeForce 3 Ti。
規格方面,Radeon 8500擁有4條像素渲染管線,這與GeForce 3是相同的,但是8500擁有2個頂點著色單元,而GeForce 3只有1個,這就使得8500的理論性能更占優勢。紋理單元方面ATI放棄了管線:紋理=1:3的設計,采用了與NVIDIA相同的1:2設計,因為第3個紋理單元在多數游戲中都毫無用處,這樣雙方的紋理單元數量也完全相同。
★ 小結:DX8架構ATI更出色,NV性能更強
整體來看雙方都是重新設計的優秀架構,考慮到眾多的特色功能和技術,Radeon 8500的確要優于GeForce 3 Ti。這是在3DFX滅亡之后,第一次有一家公司對NVIDIA造成如此大的壓力,所以NVIDIA發布了更高頻率的GeForce 3 Ti 500才勉強奪回性能之王的寶座。當然NVIDIA成熟穩定的驅動和長期積累的用戶口碑以幫助GeForce 3 Ti力壓Radeon 8500系列。
后期NVIDIA推出更多管線的GeForce 4 Ti自然擁有更強的DX8性能,但考慮到ATI方面沒有與之相對應的產品,就不做對比了,因為ATI已經直接進入了DX9時代。
● DirectX 9.0:高精度渲染時代來臨
2002年底,微軟發布DirectX 9.0,如果從技術規格上看,DX9似乎沒有DX7和DX8那種讓人眼前一亮的革命性技術,它只是將ShaderModel版本從1.0升級到2.0而已。其實不然,此次ShaderModel指令集的改進讓圖形渲染畫質提高到了新的水平。
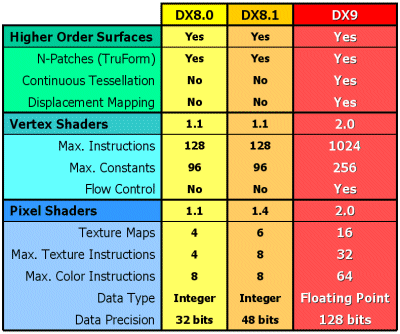
首先,PixelShader 2.0具備完全可編程架構,能對紋理效果即時演算、動態紋理貼圖,還不占用顯存,理論上對材質貼圖的分辨率的精度提高無限多;另外PS1.4只能支持28個硬件指令,同時操作6個材質,而PS2.0卻可以支持160個硬件指令,同時操作16個材質數量,新的高精度浮點數據規格可以使用多重紋理貼圖,可操作的指令數可以任意長,電影級別的顯示效果輕而易舉的實現。

3DMark03中的最后一個場景就是DX9渲染,讓人眼前一亮
其次,VertexShader 2.0通過增加頂點指令的靈活性,顯著的提高了老版本的頂點性能,新的控制指令,可以用通用的程序代替以前專用的單獨著色程序,效率提高許多倍;增加循環操作指令,減少工作時間,提高處理效率;擴展著色指令個數,從128個提升到256個。

Radeon 9700所提供的HDR Demo
另外,增加對浮點數據的處理功能,以前只能對整數進行處理,這樣提高渲染精度,使最終處理的色彩格式達到電影級別。突破了以前限制PC圖形圖象質量在數學上的精度障礙,它的每條渲染流水線都升級為128位浮點顏色,讓游戲程序設計師們更容易更輕松的創造出更漂亮的效果,讓程序員編程更容易。
★ 首款DX9顯卡——Radeon 9700
當NVIDIA沉浸于GeForce 4 Ti大獲全勝的DX8時代時,ATI在DX9標準正式確立之前就提前發布了Radeon 9700顯卡,打得NVIDIA措手不及。這款產品來得如此突然,以至于ATI發布之時甚至沒有提供相關技術PPT/PDF。

由于DX9相比DX8并沒有改變3D渲染流程,僅僅是強化了ShaderModel指令集,因此R300的架構相比R200改進并不大,主要的變化是規模的擴充與外圍控制模塊的加強。比如:首次使用256bit顯存控制器、類似CPU的FCBGA封裝、更先進的紋理壓縮技術以及后期處理單元。
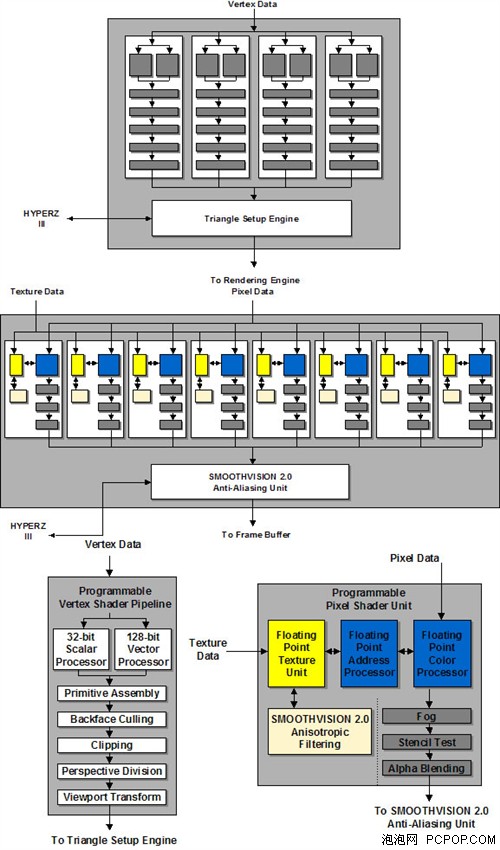
R300的頂點和像素著色單元結構
當然,R300的Shader單元經過了重新設計,定址、色彩和紋理單元都支持浮點運算精度,這是它能夠完美運行DX9程序的關鍵。R300核心擁有8條像素渲染管線及4個頂點著色單元,每條像素管線中只有1個紋理單元。至此ATI的像素與紋理的比例從1:3到1:2再到1:1,在DX9C時代將會進一步拉大至3:1,也就是風靡一時的3:1架構,當然這是后話了。
★ NVIDIA遭遇滑鐵盧——GeForce FX 5800
NV30核心采用了業界最先進的0.13微米工藝制造,并使用了最高頻率的GDDR2顯存,而且發布時間較晚,理應占盡優勢才對。但是這一次NVIDIA沒能跟上微軟的步伐,不僅在時間上晚于ATI,而且在DX9技術方面也未能超越。NV30的架構存在較大的缺陷,NVIDIA艱難的完成了從DX8到DX9的過渡,但結果很不理想。
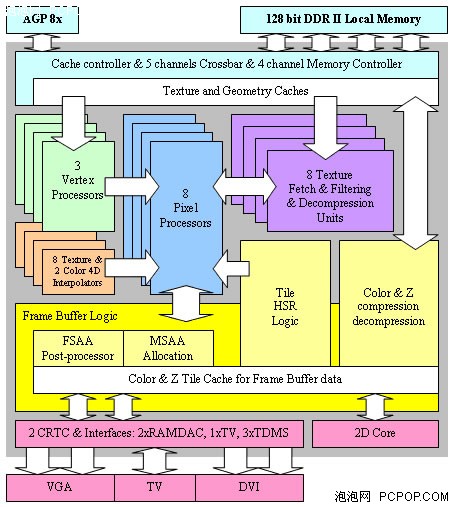
從宏觀上說,NV30的整體架構更像是一個DX7(固定功能TRUE T&L單元)、DX8(FX12combiner整數處理單元)、DX9(浮點像素單元)的混合體。而在DX9的應用中,不能出現非浮點精度的運算,所以前兩者是不起作用的,造成了NV30晶體管資源的浪費,同時也影響了性能。
NV30的PiexlShader單元沒有Co-issue(標量指令+矢量指令并行處理)能力,而在DX9中,單周期3D+1D是最常見指令處理方式,即在很多情況下RGB+A是需要非綁定執行的,這時候NV30就無法并行執行,指令吞吐量大大降低。其次,NV30沒有miniALU單元,也限制了NV30的浮點運算能力(在NV35中DX8整數單元被替換為miniALU)。
另外,NV30在寄存器設計(數量及調用方式)、指令存儲方式(讀寫至顯存)等方面也有缺陷。NV30的寄存器數量較少,不能滿足實際程序的需要。而且,用微軟的HLSL語言所編寫的pixel shader2.0代碼可以說NV30的“天敵”,這些shader代碼會使用大量的臨時寄存器,并且將材質指令打包成塊,但是NV30所采用的顯存是DDR-SDRAM,不具備塊操作能力。同時,NV30材質數據的讀取效率低下,導致核心的Cache命中率有所下降,對顯存帶寬的消耗進一步加大。
由于NV30是VILW(超長指令,可同時包含標量和SIMD指令)設計類型的處理器,對顯卡驅動的Shader編譯器效率有較高的要求。排列順序恰當的shader代碼可以大幅度提升核心的處理能力。在早期的一些游戲中,這種優化還是起到了一定的作用。但對于后期Shader運算任務更為繁重的游戲則效果不大。
最終,雖然NV30與上代的NV25相比架構變化很大,但性能方面全面落后與對手的R300。不過NV30的架構還是有一定的前瞻性,ATI的R600在Shader設計方面與NV30有很多相似之處。
★ 小結:非“真DX9架構”導致NV30失敗
現在再來看看,相信沒人會認為DX9的改進有限了。正是由于NVIDIA沒能適應DX9所帶來ShaderModel指令的諸多改進,采用DX8+DX9混合式的架構,才導致NV30存在很大缺陷,在運行DX9游戲時效率很低。另外冒險采用先進工藝、不成熟的GDDR2顯存、128bit位寬這些都極大的限制了NV30的性能,即便在DX8游戲中都無法勝過R300。
而ATI則占據天時地利人和等一切優勢,完全按照DX9標準而設計,甚至在DX9標準確立之前就早早的發布了DX9顯卡,這不免讓人感覺ATI和微軟之間存在微妙的關系,“陰”了NVIDIA一把。
這是DirectX歷史上唯一一次半代更新就引起渲染大波的版本,DirectX 9.0c,大名鼎鼎的HDR技術誕生。
● DirectX 9.0c:無與倫比的光影渲染
DX9也是一次革命性的改進,但由于沒有代表性的關鍵技術,以至于被廣大用戶所忽視,其實ShaderModel從1.0升級到2.0給圖像渲染品質帶來了巨大的提升。DX9的第三個版本DX9C則更進一步,將ShaderModel從2.0升級至3.0,這一次又能帶來什么呢?
ShaderModel 3.0除了繼續擴展指令長度之外,還提升了指令執行能力,它開始支持動態分支操作,像素程序開始支持分支操作(包括循環、if/else等),支持函數調用。因此DX9C和SM3.0標準的推出,可以說是DirectX發展歷程中的重要轉折點。
SM3.0除了取消指令數限制和加入位移貼圖等新特性之外,更多的特性都是在解決游戲的執行效率和品質上下功夫,SM3.0誕生之后,人們對待游戲的態度也開始從過去單純地追求速度,轉變到游戲畫質和運行速度兩者兼顧。因此SM3.0對游戲產業的影響可謂深遠。
以上諸多改進相信很多人都不關心也不想知道,絕大多數人記住的只有一個,那就是只有DX9C顯卡才支持HDR技術,因為HDR所帶來華麗的光影效果給所有人都留下了深刻的印象,那種從暗淡無光到流光溢彩的美好回憶,可以說是前無古人后無來者的!
HDR的全稱是High Dynamic Range,即高動態范圍,是一種色彩存儲方式,在游戲用于存儲渲染和光照數據。HDR渲染可以用4句話來概括:1.亮的地方很亮;2.暗的地方很暗;3.亮暗部的細節非常非常明顯;4.所有光照為實時計算生成,可模擬人眼視網膜動態改變明暗細節。

HDR(高動態范圍)渲染
在DX9C之前,HDR已經得到了廣泛應用,一般有FP16 HDR(半精度浮點型)和INT32 HDR(整數型),但效果都不如人意,FP16的動態范圍不夠大,而IN32的效率很低,因此這些HDR格式并未帶來震撼效果。而FP32 HDR(32bit浮點格式)的誕生則大大拓展了明暗度擴展空間,使得游戲的光影效果有了質的提升,當年的《細胞分裂》、《FarCry》、《3DMark06》等一系列游戲開啟HDR后的畫面讓人驚訝不已!
★ 首款DX9C顯卡——GeForce 6800
在經歷了GeForce FX系列慘痛的失敗后,NVIDIA痛定思痛,要挽回在高端產品上的失利局面,僅靠架構已完全定型的NV3x系列作一定程度的增補顯然是很難實現的。NVIDIA將更大的希望押寶在了新一代產品之上,它吸取了上一代產品的教訓,重新設計的架構和完整支持DX9C標準,讓這款顯卡以全新的形象展現在用戶面前。甚至有分析家評論GeForce 6800和GeForce FX簡直不是一家公司設計的產品,其架構變化之大可見一斑!
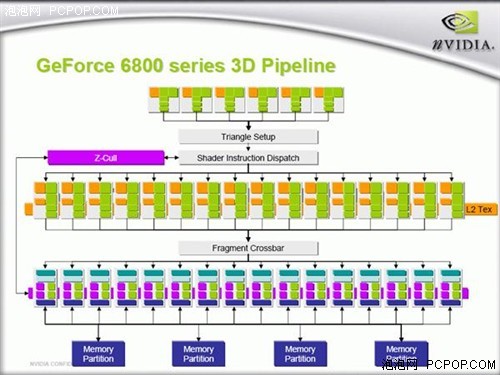
NV3X最大的弊端就是像素渲染單元效能低下,而NV40最強大之處就在像素單元架構部分。NV40擁有多達16條像素渲染管線暫且不談,其每一個PSU的結構都值得探討,NVIDIA將其稱為Superscalar(超標量)的設計。普通的像素渲染管線只提供一組著色器單元,每個周期最多只能執行四組運算,而NV40的超標量架構則內含第二組著色器單元,讓每個周期的運算量增加一倍。
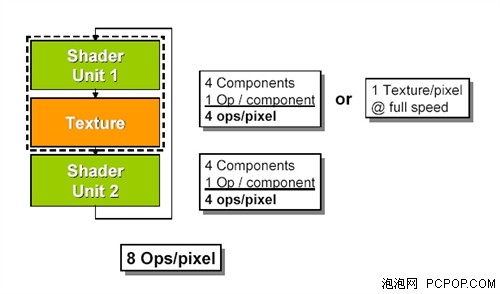
NV40的像素渲染管線結構
正因為如此,對手ATI的X800系列雖然在硬件規格上與NV40完全相同,但在DX9b游戲中的性能差距依然不小,這就是超標量架構的優勢。當然固步自封的ATI在X800時代依然僅支持DX9b,無法開啟HDR,喪失了很多賣點,讓用戶大失所望。
6800的成功讓NVIDIA風光無限,整個GeForce 6家族在各個價位都力壓對手的X800家族,而且完美的架構使得NVIDIA可以輕易的擴充規模,發布了擁有多達24條像素渲染管線的第二代DX9C顯卡——GeForce 7800系列(其架構基本沒變,只做了些許優化,這里就不多做介紹了)。
★ 支持HDR+AA的DX9C顯卡——X1800/X1900
X800的對手是6800系列,但它既沒有性能優勢,也不支持DX9C/HDR,這使得ATI經歷了9700/9800系列短暫的輝煌之后再次陷入被動局面。于是,ATI開始研發下一代GPU,改良架構,準備重奪王位。但事與愿違,R520核心的X1800XT雖然使用了全新的架構,完美支持DX9C,但依然沒能擊敗已經發布半年之久的7800GTX,因為X1800XT依然只有16條像素渲染管線,而7800GTX擁有多達24條,差距如此之大,根本無法用新架構的效率及高頻率來彌補。
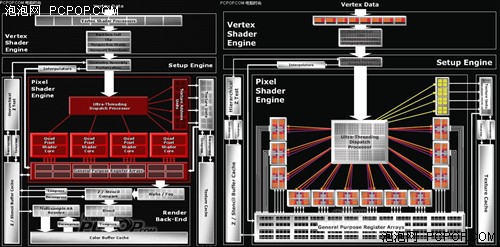
R520與R580的架構幾乎完全相同,不同的只有像素單元數量
當時誰都沒有料到ATI還預留了一手,原來R520這種架構的實力遠不止16條像素渲染管線這么簡單,ATI完全顛覆了傳統“管線”的概念,R580核心緊隨其后,將像素渲染單元提升只48個之多,整整是R520的3倍!而頂點渲染單元和紋理單元以及GPU其它所有模塊都沒有做任何改動。
從R520到R580的這種改變當時令所有人都很費解,因為包括G70和R420在內的以往所有GPU都是管線式架構,就是像素渲染單元內部包含了紋理單元,一般像素和紋理的比例是1:2或者1:1。而R520首次將像素單元和紋理單元拆分開來,成為獨立的設計,所有的像素單元都可以互相共享所有紋理單元資源,R520的像素和紋理比例依然是1:1,而R580的比例則瞬間提升至3:1,相信資歷較老的玩家一定記得ATI當年大肆鼓吹“三比一架構”。
這樣設計是因為ATI發現了游戲的發展趨勢,像素渲染的比重越來越高,而紋理貼圖的增長比較緩慢,相信大家還記得當年ATI的DX7顯卡,其一條管線中包括了3個紋理單元,以前是1:3后來是1:2接著變成1:1,現在被ATI一舉提升至3:1。雖然當時很多人都不好理解,但從現在的發展來看,像素與紋理的比例越拉越大,DX10時代大概是3:1,DX11時代則變成了5:1甚至更高!
除了具有前瞻性的3:1架構外,X1000架構還有另一大絕招就是HDR+AA技術。大家知道6800系列連續兩年都是市面上唯一的DX9C顯卡,當時所有的DX9C游戲都是基于NVIDIA的架構而開發,當使用N卡開啟HDR特效時(準確的說是FP32格式),會占據原本屬于MSAA的緩沖區,導致HDR和AA無法共存。HDR是DX9C的代表技術,能大大提升畫面效果,而AA消除鋸齒也能大幅改善畫質,這兩項關鍵特效無法同時開啟讓玩家們很郁悶。
ATI的DX9C產品比NV晚了一代,ATI意識到了DX9C的這一缺陷之后,在其架構設計之初就考慮到了HDR和AA共存的問題,因此特別設計了專用的緩沖區,可以通過游戲或者驅動重新指定MSAA的緩存位置,從而同時開啟HDR+AA。遺憾的是修改游戲或驅動兼容性并不好,支持的游戲也不多,雖然這確實是一個很大的賣點,ATI銳意進取的精神也值得尊重,但最終效果還是不如人意。
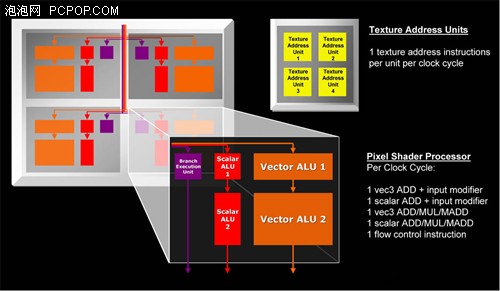
另外,X1000也改進了像素著色單元的內部結構,每個像素單元都擁有兩個算術邏輯單元和一個分支執行單元,其中ALU1只能執行加法(ADD)計算,ALU2能執行包括加法、乘法(MUL)、乘加(MADD)各類運算,兩個ALU最高可以執行兩條指令(3D+1D)。為了控制如此龐大的像素單元,ATI還針對SM3.0的特性改進了動態流控制功能,大大改進了SIMD架構的動態分支性能,讓像素著色效能得到提升。
功夫不負有心人,全新架構并且擁有多達48像素單元的X1900XTX,性能比X1800XT獲得了大幅提升,完勝對手的7900GTX,而且越新的游戲優勢越明顯。強大的X1900XTX迫使NVIDIA推出雙G71核心的7950GX2來對抗,雖然7950GX2單卡超越了X1950XTX,但雙卡的話則因效率問題依然是A卡占優。
★ 小結:DX9C時代雙方架構各有所長
DX9C是一代經典API,至今依然有很多游戲無視DX10/DX11,堅守DX9C平臺,以至于HDR+AA的問題被遺留至今依然沒能得到完美解決。NV40是因為發布較早沒能解決這一難題,G70則是擴充像素和頂點的產物,也沒能解決。
ATI在X800時代未能搶得先機,因此在X1000架構當中花了很多心思,爭取做最完美的DX9C顯卡,他們確實做到了這一點,無論架構和性能都有優勢。但由于晶體管規模太大,功耗表現不如人意,因此在市場方面X1000與GF7相比并無優勢。
以往的DirectX游戲無論多么優秀,始終都會有OpenGL引擎和游戲站出來發起挑戰,而且其畫面還相當不錯。但DX9C之后,就只有ID Software還在負隅頑抗了,到了DX10時代,再也沒有任何一款OpenGL能與DX游戲相抗衡,微軟終于一統江湖!
● DirectX 10.0:統一渲染架構和幾何著色
DX10又是一次大革命,除了將ShaderModel從3.0升級至4.0版本外,還有兩項非常重要技術:
第一:引入統一渲染架構,從此不再區分像素與頂點著色單元,而是由流處理器單元按照負載動態的執行包括像素和頂點在內的各種著色指令:
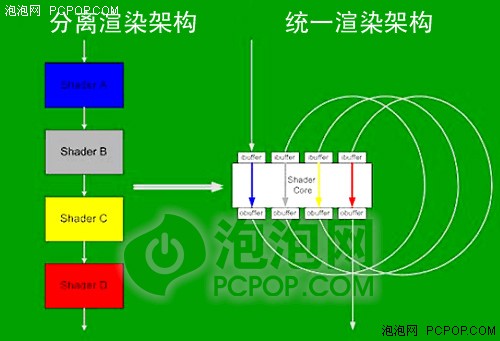
DX11引入統一渲染架構,不同的著色單元不會再出現空閑浪費資源的情況
第二,引入全新的幾何著色單元,它第一次允許由GPU來動態的生成和銷毀幾何圖元數據,使GPU可以在不用CPU干涉的條件下進行反復運算,許多以前無法實時使用的算法現在都可以在GPU中使用了。

此外,DX10還引入了兩種新的HDR格式,避免了HDR和AA不兼容的情況出現,并提升了HDR效率;DX10還大大改進了紋理貼圖的精度和效率;其它大大小小的改進有數十項之多,這里就不多做介紹了。
統一渲染架構的引入要求NVIDIA和ATI雙方必須放棄以往的模式,重新設計全新的GPU架構,G80和R600之爭拉開了帷幕……
★ 首款DX10顯卡——GeForce 8800
無論從哪個方面來看,GeForce 8800與DX9時代的Radeon 9700都非常相似,微軟的新一代API尚未正式發布,而新顯卡居然開賣了大半年,雖然沒有新游戲的支持,但在老游戲下的性能依然非常完美。因此每一代成功的顯卡最關鍵的還不是API,還是核心架構。DX10是API的又一次革命,而G80則是GPU架構的一次偉大革命:
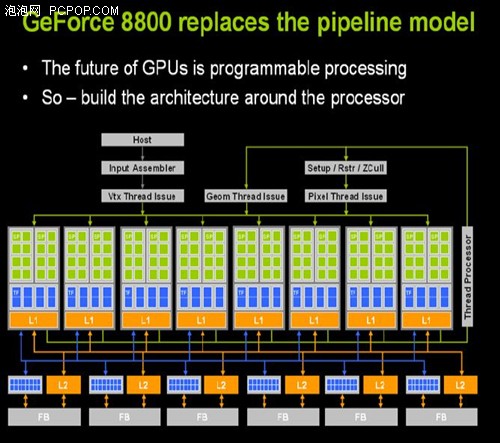
如果說R580像素與紋理3:1的比例讓人很費解的話,那么G80的流處理器設計則讓用戶們一頭霧水:從G71的24條像素管線一下變成了128個流處理器,哪來的這么多?
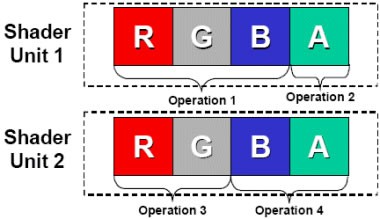
傳統的GPU Shader架構
傳統的Shader不管是像素還是頂點,其實都是SIMD(單指令多數據流)結構,就是個4D矢量處理器,可以一次性的改變像素的RGBA數據或者頂點的XYZW數據。而G80的流處理器則是1D標量處理器,它一次只能計算像素和頂點4個數據中的1個,如此說來效率豈不是很低?
當然不是,因為隨著游戲的發展,GPU所要處理的指令已經不是4D這種常規數據流了,進入DX10時代后Z緩沖區(1D)或紋理存取(2D)等非4D指令所占比重越來越多,此時傳統的Shader單元在執行此類指令時的效率會降至1/2甚至1/4,即便有Co-issue技術的支持效率改進也十分有限。
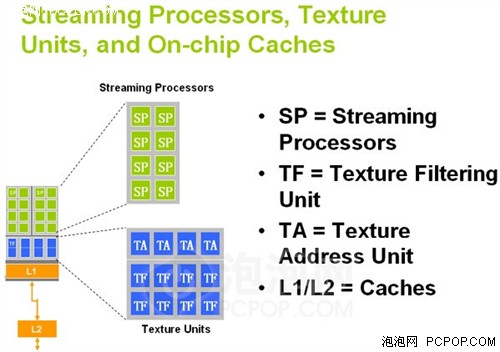
G80的SP
而G80 1D標量流處理器執行各種類型指令時的效率都能達到100%,這也就是NVIDIA對于GPU架構大換血的主要目的。G80的這種架構被稱為MIMD(多指令多數據流),其特色就是執行效率非常高,但也不是沒有缺點,理論運算能力偏低、晶體管消耗較大,當然由于對手產品實力不行,這些缺點在很長一段時間內都沒有被發現。
而且NVIDIA的1D標量流處理器還可以異步工作在超高頻率之下,一般是GPU核心頻率的兩倍,由此大幅提升了渲染能力。這一技術ATI至今都未能實現。
★ ATI的DX10圖形架構——R600
與革命性的G80架構不同,R600身上有很多傳統GPU的影子,其Stream Processing Units很像上代的Shader Units,它依然是傳統的SIMD架構。
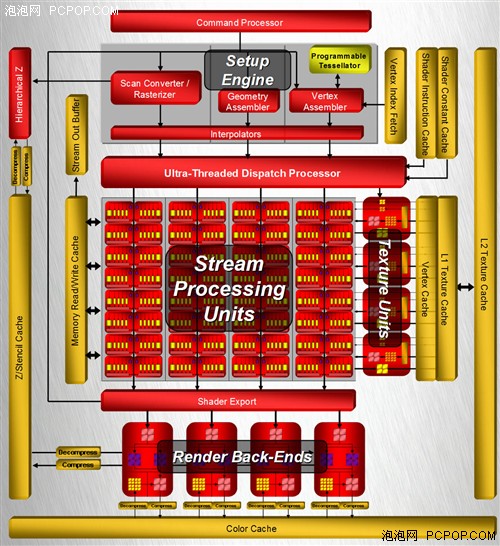
R600擁有4個SIMD陣列,每個SIMD陣列包括了16個Stream Processing Units,這樣總共就是64個,但不能簡單地認為它擁有64個流處理器,因為R600的每個Units內部包含了5個ALU:
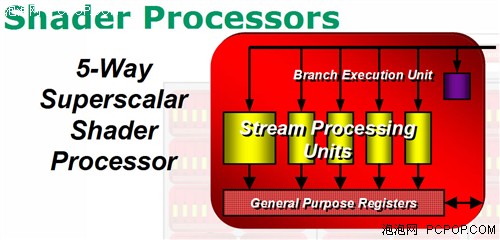
我們來仔細看看R600的流處理器架構:Branch Execution Unit(分歧執行單元)就是指令發射和控制器,它獲得指令包后將會安排至它管轄下5個ALU,進行流控制和條件運算。General Purpose Registers(通用寄存器)存儲輸入數據、臨時數值和輸出數據,并不存放指令。
由于內部的5個1D ALU共享同一個指令發射端口,因此宏觀上R600應該算是SIMD(單指令多數據流)的5D矢量架構。但是R600內部的這5個ALU與傳統GPU的ALU有所不同,它們是各自獨立能夠處理任意組合的1D/2D/3D/4D/5D指令,完美支持Co-issue(矢量指令和標量指令并行執行),因此微觀上可以將其稱為5D Superscalar超標量架構。
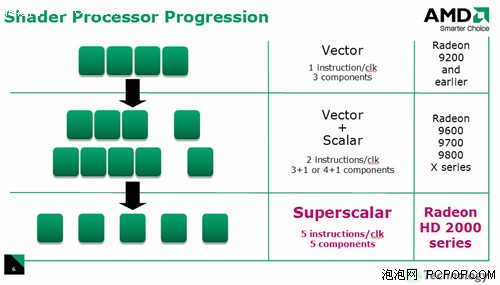
通過上圖就可以清楚的看到,單指令多數據流的超標量架構可以執行任意組合形式的混合指令,在一個Stream Processing Units內部的5個ALU可以在單時鐘周期內進行5次MAD(Multiply-Add,乘加)運算,其中比較“胖”的ALU除了MAD之外還能執行一些函數(SIN、COS、LOG、EXP等)運算,在特殊條件下提高運算效率!
現在我們就知道R600確實擁有64x5=320個流處理器。R600的流處理器之所以能比G80多好幾倍就是得益于SIMD架構,可以用較少的晶體管堆積出龐大規模的流處理器。但是在指令執行效率方面,SIMD架構非常依賴于將離散指令重新打包組合的算法和效率,正所謂有得必有失。
★ 總結:DX10架構G80笑到了最后
通過前面的分析我們可以初步得出這樣的結論:G80的MIMD標量架構需要占用額外的晶體管數,在流處理器數量和理論運算能力方面比較吃虧,但卻能保證超高的執行效率;而R600的SIMD超標量架構可以用較少的晶體管數獲得很多的流處理器數量和理論運算能力,但執行效率方面卻不如人意。
G80的架構顯然要比R600改進更為徹底,所以打從一開始G80/G92就遙遙領先與R600/RV670,其后續產品GT200一如既往的保持領先優勢,但幅度沒有G80那么大了,因為R600的架構的特性就是通過數量彌補效率的不足。
● DirectX 11注重效率:關鍵特性曲面細分
DX9C和DX10聽起來非常完美,但也有明顯的缺點,就是系統資源開銷很大,運算效率比較低,所以DX11的重點就落在了改進渲染效能方面。DX11除了將ShaderModel從4.0升級至5.0外,還有兩項最重要的改進就是Tessellation和DirectCompute,其中DirectCompute的指令集主要來源于ShaderModel 5.0。

當然還有多線程渲染、增強的紋理壓縮格式等其它若干改進,在我們之前的HD5800和GTX480評測中已經做過詳細介紹了,因此就不再贅敘。

Tessellation被譯為鑲嵌,就是一種能讓GPU在模型內部自動插入新的頂點,從而讓幾何圖形變得無比復雜細膩的技術,它可以在很少的性能損失下換取明顯的畫質提升。DX11游戲在畫面上的改進主要來自于曲面細分技術,而且曲面細分還能帶來很多意想不到的特效!
為了配合Tessellation技術,微軟還專門設計了兩種全新的Shader著色器,Hull和Domain,以便更精確的控制鑲嵌位置,并置換位移貼圖。這就與DX9/DX10時代的Tessellation有著本質區別,無法照抄照搬。
DirectCompute則是微軟的GPU計算API,可以讓GPU處理一些非圖形類指令,獲得遠超CPU的性能。不過目前DirectCompute主要還是用在圖形渲染后處理器方面,可以產生非常逼真的景深、透明效果。
★ 首款DX11顯卡——HD5800
在經歷了DX10時代R600的失利之后,ATI對于微軟新一代API十分重視,第一時間對于DX10.1提供了支持,可惜DX10.1相對于DX10改進有限,并不像DX9C那樣帶來震撼的HDR技術,因此未能得到足夠的重視。但ATI積極向上的精神讓它在DX11時代搶得先機。

但令人奇怪的是,ATI并沒有因為DX11而改變架構,而是幾乎原封未動的照搬了上代RV770核心,除了顯存位寬維持256bit不變之外,Cypress的其它所有規格都正好是RV770的兩倍,而且在流處理器部分可以看作是雙核心的設計,幾乎就是并排放置了兩顆RV770核心。
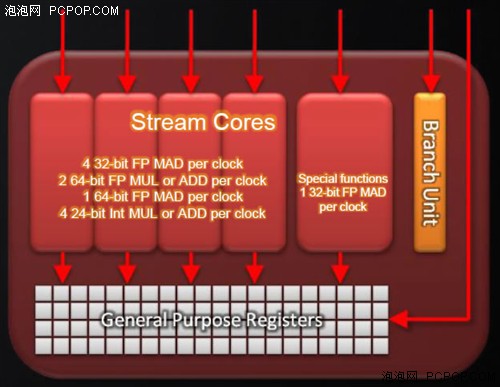
在流處理器部分,RV870相對于RV770改進有限,只是加入了DX11新增的位操作類指令,并優化了Sum of Absolute Differences(SAD,誤差絕對值求和)算法。基本上,除了新增DX11支持和擴充規模外,Cypress與RV770在架構方面沒有本質區別。
HD5000系列的主要優勢就是功耗控制比較出色,另外功能方面Eyefinity多屏顯示以及次世代音頻源碼輸出都很有特色,架構方面確實沒有多少亮點。
★ 完全針對DX11而設計的顯卡——GTX480
HD5800這一領先,又是半年,這次NVIDIA的陣腳并沒有像NV30那樣被打亂,而是按部就班的按照既定的設計目標推出全新架構的一代產品,而不是像ATI那樣在上代產品基礎上改改就發布新品,因為DX11是全新的API,必須為DX11新的特性做相應的優化,才能獲得最出色的DX11效能。

GF100核心是既G80和R600之后,近4年來GPU架構改進最大的一次,主要體現在以下四個方面:
1. GPU核心處理部分被劃分為4個區塊(GPC),每個區塊內部囊括了所有主要的圖形處理單元。它代表了頂點、幾何、光柵、紋理以及像素處理資源的均衡集合。除了ROP功能以外,GPC可以被看作是一個自給自足的GPU,所以說GF100就是一顆四核心的GPU。
2. 每個GPC都擁有一個獨立的Raster Engine(光柵化引擎),負責邊緣設置、光柵器消隱以及Z軸壓縮功能。可大幅提升GPU在高分辨率下的性能。
3. 每組SM都擁有一個獨立的PolyMorph Engine(多形體引擎),負責GPU的幾何圖形轉換以及Tessellation曲面細分功能,徹底消除GPU的幾何性能不足的瓶頸,從而大幅提升DX11性能。
4. GPU的一二級緩存都經過了重新設計,架構上更類似于Intel的多核CPU,改進流處理器和紋理單元的性能,進一步提升MIMD架構的效能。
和上代的GT200相比,GF100的所有模塊幾乎都經過了重新的設計,就連CUDA核心(流處理器)內部的ALU運算單元都針對新的浮點運算格式以及函數做了改進與優化,而不僅僅是兼容SM5.0指令集而已。相反ATI的Cypress核心與上代的RV770相比幾乎所有模塊都未做任何改進。
經過我們此前的評測來看,GTX480/470在DX10游戲中領先HD5870/5850的幅度并不大,20-30%左右的優勢都在意料之中。但在DX11游戲和應用中性能優勢十分顯著,尤其是Tessellation性能遙遙領先于HD5870甚至雙核心的HD5970。DX11特效使用的越多,GTX480/470的優勢就越明顯。問題顯然出在GPU架構方面,GF100是一顆完全針對DX11設計的、采用的全新架構的GPU,而Cypress核心只不過是上代DX10架構外加SM5.0指令集而已,只能說支持DX11但具體的效能不容樂觀。
★ 小結:DX10架構無法滿足DX11的需要
通過以上分析可以看出,由于HD5800的架構與HD4800完全相同,只是流處理器規模翻倍而已,因此它確實擁有出色的DX10/10.1性能,但DX11的性能卻很一般。因為DX11是一款全新的API,并不是針對DX10的小修小補,很多特性不是兼容SM5.0指令集就能做得到的。
ATI雖然通過搶先發布DX11顯卡賺得了滿堂彩,但卻沒能經得住時間的考驗,未能重現DX9時代R300的輝煌。因為時代變了,當年的R300是全新的架構,完美支持DX9,而NV30架構存在很多缺陷。而現在正好相反,Cypress完全是新瓶裝舊酒,而GF100則是真正的DX11架構,這在所有DX11測試中都得到了證實。
● 回顧GPU和DirectX發展史,有規律可循
回顧DirectX的發展史,就會發現雖然微軟一直在左右著兩大顯示巨頭的發展,但這只是外因而不是內因,真正決定勝敗的關鍵還是在GPU體系架構方面,這才是雙方設計實力的體現。
縱觀NVIDIA和ATI近幾年的交鋒:DX7 NV占優,DX8前期ATI占優后期NV反超,DX9 ATI優勢明顯,DX9C前期NV大獲全勝后期被反超,DX10 NV一路遙遙領先,DX11 ATI搶得先機但又被NV反超——似乎毫無規律可循,實則不然,且聽筆者慢慢道來:
★ DirectX重大版本更新,GPU必采用全新架構
從DX7、DX8、DX9、DX9C、DX10,每逢DirectX有重大版本更新時(主要是ShaderModel指令集),GPU架構都會做大幅度的調整,甚至是拋棄老架構重新設計一套新的架構,NVIDIA和ATI雙方無一例外!而且新的架構總是能夠取得勝利,因為全新的架構完全針對新的API設計,能夠徹底發揮出新技術和特性的優勢,確保發揮出預期的效果。
比如DX7 DX8時代,雙方都是全新的架構,產品的性能其實相差不多,DX8的Radeon 8500甚至超越了GeForce 3,GeForce 4的優勢是建立在ATI已經放棄DX8提前進入DX9時代的基礎上;DX9時代全新架構的R300大獲全勝,NV30的混合架構效率極差一敗涂地;DX9C時代NV40重返王座,其后續產品G70/G71因為沒有更換架構,在ATI全新的R580面前失去了以往的輝煌;DX10時代G80/G92革命性的架構一路遙遙領先,R600的架構脫胎于R580,表現不甚理想,曾一度遭到懷疑,但隨著800SP RV770誕生后,其出色的表現證明了ATI當初的設計思路其實并沒有錯,但始終沒有得到翻身的機會。

NVIDIA要讓GT200添加DX11支持是很容易的,但并沒有這么做
★ DirectX半代更新,GPU不會更改架構
而DirectX的半代更新,比如DX7.1、DX8.1、DX9.0b、DX10.1這些版本(DX9C不算,因為其ShaderModel從2.0升至3.0),雙方都不會更改GPU架構,只是在上代產品基礎上小修小補,通過擴充指令集的方式兼容新API即可。尤其是DX10.1這個版本,由于改進太少,雙方竟然將G80/R600這一套架構用了5年之久,這在GPU發展史上是極為罕見的!
當然如果DirectX版本停滯不前的話,GPU架構更不會更換,比如DX9C時代的GF6和GF7,DX10時代的GF8/GF9/GT200和RV670/RV770。
★ 唯一的例外——首款DX11顯卡HD5000
以上結論看起來很有意思,但是唯獨DX11是個例外:ATI對RV770(還是R600架構)沒有做任何更改就制造出了DX11顯卡,這樣的做法確實讓人感到意外,但也不難理解,ATI信奉“先行者勝”的理念,認為只要搶先發布DX11顯卡就能取得成功。
但在NVIDIA發布GF100之后,HD5000低下的DX11性能讓人非常失望,HD5000的確是優秀的DX10/10.1顯卡,但他不能算是一款合格的DX11顯卡,最終HD5000也難逃宿命,勝利屬于全新架構的NVIDIA GF100。

★ HD5000只是過渡產品,ATI真DX11顯卡尚未露面
或許我們現在下結論還為時過早,但ATI的做法已經證明了DX11確實需要一套全新的GPU架構,HD5000只不過是臨時性架構,ATI下一代的DX11核心“南方群島”和“北方群島”都在緊鑼密鼓的開發當中,據稱“北方群島”將會是一套徹底改頭換面的架構,而“南方群島”將采用混合式的架構,僅在外圍模塊使用新的技術,內核部分依然保持不變。
想要在DX11性能方面取得突破,就必須將現有的架構推倒重新來過,NV30的混合型架構一敗涂地就是很好的例子。HD5000確實擁有不俗的DX10性能,但現在越來越多的用戶需要真正的DX11顯卡,因為DX11是大勢所趨,其普及速度之快超越了以往任何一代API。
★ 目光放長遠一點,真DX11架構的顯卡更值得期待
目前來看,真正為DX11設計的GPU只有GF100這一顆,GTX480/470定位較高難入平常百姓家。不過其后續產品也非常值得期待,我們知道GF100強悍的動力源自于內部的光柵化引擎和多形體引擎,即便將GF100的規格削減為1/2甚至1/4,它依然擁有不俗的幾何性能和Tessellation性能,而且功耗將會控制的更好,非常值得中端主流用戶期待。■
網載 2012-07-10 21:14:09
評論集
暫無評論。
稱謂:
内容:
驗證:
返回列表